记录 Rollup 初代是如何分析代码的

在使用 JS 开发的过程中,我们常常会希望将完成一部分功能的代码分隔成单独的文件,这样带来的问题是在浏览器中运行时会产生很多小文件请求,解决办法就是使用模块打包工具将这些小文件归集在一个文件中,Browserify、Webpack、Rollup 等工具都可以做到,Rollup 使用 JavaScript 的 ES6 版本中包含的新标准化代码模块格式,而不是以前的 CommonJS 和 AMD 等特殊解决方案,利用这一点 Rollup 可以对代码进行静态分析只将依赖中引用到的最小部分打包到最后的产出中。
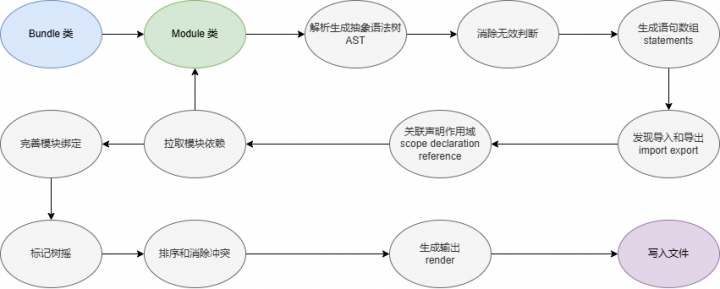
对比 rollup-init 的源码和 rollup 很早期发布的版本源码,发现 rollup 本身初期使用了 Gobble 进行打包,后续则是利用 rollup 自身不断对自身进行优化,这被称作模块打包器的自举,自举(Bootstrapping)是一个计算机科学和软件工程中的术语,它指的是一个系统或程序能够使用自身的功能来重新构建或重新初始化自己的过程。
创建测试环境
本篇笔记主要记录 rollup-init 这个版本的代码实现,首先依旧是创建测试环境,先把源码克隆到本地,在根目录执行 npm install 安装依赖,接下来执行 npm run build 打包代码,这个过程实际执行的是 rollup -c 命令,我们知道每当执行 npm run,就会新建一个 Shell,在这个 Shell 里面执行指定的脚本命令,特别的是,npm run 新建的这个 Shell,会将当前目录的 node_modules/.bin 子目录加入 PATH 变量,执行结束后,再将 PATH 变量恢复原样。依赖成功安装后 rollup 已经被加入到 node_modules/.bin 子目录,因此 rollup -c 命令可以被执行。
rollup 命令行工具会默认读取位于根目录的名为 rollup.config.js 的配置文件,这个文件配置了入口地址 src/rollup.js 和构建地址 dist/rollup.js(CommonJS 规范)。
接下来我们就可以编写测试程序了,在 test 目录下面新增 me 目录存放自己的测试文件,然后新建 index.js 写入以下代码:
const rollup = require( '../../dist/rollup' )
const options = {
entry: './main.js',
dest: './dist.js',
}
rollup.rollup(options).then(res => {
res.write(options)
})
这段代码的作用是以 main.js 为入口文件构建代码到 dist.js,你可以在 main.js 中写入任何代码然后在 dist.js 中观察输出。执行 node index.js 即可完成构建。
Bundle
打开入口文件 src/rollup.js,第 39 行定义并导出了 rollup 函数,这个函数就是测试程序里面 rollup.rollup 函数,入参为构建选项 options。第 54 行函数内创建了 Bundle 类的实例 bundle,传入了构建选项 options,接下来第 56 行执行了 bundle.build 方法。
打开 src/Bundle.js,第 21 行定义并导出了 Bundle 类,第 86 行定义了类的 build 方法,在 build 方法中第一行执行了 this.resolveId,这个函数在第 44 行定义。
......
import first from './utils/first.js';
......
import ensureArray from './utils/ensureArray.js';
......
import { ......, resolveId } from './utils/defaults.js';
......
export default class Bundle {
constructor ( options ) {
......
this.resolveId = first(
[ id => this.isExternal( id ) ? false : null ]
.concat( this.plugins.map( plugin => plugin.resolveId ).filter( Boolean ) )
.concat( resolveId )
);
......
if ( typeof options.external === 'function' ) {
this.isExternal = options.external;
} else {
const ids = ensureArray( options.external );
this.isExternal = id => ids.indexOf( id ) !== -1;
}
......
}
......
}
export default function first ( candidates ) {
return function ( ...args ) {
return candidates.reduce( ( promise, candidate ) => {
return promise.then( result => result != null ?
result :
Promise.resolve( candidate( ...args ) ) );
}, Promise.resolve() );
};
}
其中 first 函数利用柯里化将传入的参数(candidates 数组里面为待执行函数)固定并返回一个函数,返回的函数在执行时会依次调用传入参数中的函数并返回第一个不等于 null 的结果(Promise),因为我们现在还没有设置 plugin 参数,因此可以忽略 plugin.resolved,这样 first 的传入参数就可以简化为:
[ id => this.isExternal( id ) ? false : null, resolveId ]
利用 plugin.resolveId 可以不走默认的解析方法,比如直接检查 node_modules 目录解析路径。
那么在执行第 90 行的 this.resolveId 方法时会依次将传入的 this.entry 参数传递到上面数组中的两个函数中执行,由于我们目前没有配置 options.external,因此 this.isExternal 会返回 null,第二个函数 resolveId 会继续执行,最终的结果是解析出入口文件的完整绝对路径并返回(Promise),以下就是函数 resolveId 的定义。
export function resolveId ( importee, importer ) {
if ( typeof process === 'undefined' ) throw new Error( `It looks like you're using Rollup in a non-Node.js environment. This means you must supply a plugin with custom resolveId and load functions. See https://github.com/rollup/rollup/wiki/Plugins for more information` );
// absolute paths are left untouched
if ( isAbsolute( importee ) ) return addJsExtensionIfNecessary( resolve( importee ) );
// if this is the entry point, resolve against cwd
if ( importer === undefined ) return addJsExtensionIfNecessary( resolve( process.cwd(), importee ) );
// external modules are skipped at this stage
if ( importee[0] !== '.' ) return null;
return addJsExtensionIfNecessary( resolve( dirname( importer ), importee ) );
}
function addJsExtensionIfNecessary ( file ) {
if ( isFile( file ) ) return file;
file += '.js';
if ( isFile( file ) ) return file;
return null;
}
在 resolveId 函数中有几个处理路径的方法值得学习,贴在这里供以后参考:
export const absolutePath = /^(?:\/|(?:[A-Za-z]:)?[\\|\/])/;
export const relativePath = /^\.?\.\//;
export function isAbsolute ( path ) {
return absolutePath.test( path );
}
export function isRelative ( path ) {
return relativePath.test( path );
}
export function normalize ( path ) {
return path.replace( /\\/g, '/' );
}
node 中的 path 和 process 模块也提供了很多用于处理文件和目录路径的实用工具,比如 path.resolve 方法将路径或路径片段的序列解析为绝对路径,path.dirname 方法返回传入参数的目录名,process.cwd 方法返回 node 进程的当前工作目录。
回到 build 方法里面,下面代码中的 id 就是入口文件的完整路径。
this.resolveId( this.entry, undefined )
.then( id => {
if ( id == null ) throw new Error( `Could not resolve entry (${this.entry})` );
this.entryId = id;
return this.fetchModule( id, undefined );
})
接下来就是执行 this.fetchModule 方法获取 Bundle 模块。
Fetch Module
第 172 行定义了 fetchModule 方法,第 177 行执行了 this.load 方法,这个方法在第 54 行被定义,仍然用到了上文的 first 方法。
......
import { load, ...... } from './utils/defaults.js';
......
export default class Bundle {
constructor ( options ) {
......
const loaders = this.plugins.map( plugin => plugin.load ).filter( Boolean );
this.hasLoaders = loaders.length !== 0;
this.load = first( loaders.concat( load ) );
......
}
......
}
......
plugin.load 仍然可以被忽略,因此这里 first 函数传入的参数可以简化为:
[load]
利用 plugin.load 改变读取文件的方式,比如动态生成文件内容。
上面数组中 load 函数的作用为读取文件内容:
export const readFileSync = fs.readFileSync;
export function load ( id ) {
return readFileSync( id, 'utf-8' );
}
执行完毕后返回入口文件内容 source,第 193 行会组合成为新的数据形式:
source = {
code: source,
ast: null
}
第 203 行执行了 transform 方法,它定义在 src/utils/transform.js 第 3 行,因为传入参数 this.plugins 仍然为空,因此可以理解为只是又变换了一种数据形式返回:
source = {
code: source,
ast: null,
originalCode: source,
originalSourceMap: undefined,
sourceMapChain: [],
}
利用 plugin.transform 转换文件内容。
Module
接下来创建 Module 类的实例 module,具体传入参数如下:
const {
code,
originalCode,
originalSourceMap,
ast,
sourceMapChain,
resolvedIds
} = source;
const module = new Module({
id,
code,
originalCode,
originalSourceMap,
ast,
sourceMapChain,
resolvedIds,
bundle: this
});
打开 src/Module.js,在创建类实例的过程中,第 46 行定义了 this.magicString 属性,它是 MagicString 的实例(引入依赖 magic-string 处理字符串并生成 source map)。
export default class Module {
constructor ({ id, code, originalCode, originalSourceMap, ast, sourceMapChain, resolvedIds, bundle }) {
......
this.excludeFromSourcemap = /\0/.test( id );
......
// By default, `id` is the filename. Custom resolvers and loaders
// can change that, but it makes sense to use it for the source filename
this.magicString = new MagicString( code, {
// 生成准确的源映射
filename: this.excludeFromSourcemap ? null : id, // don't include plugin helpers in sourcemap
// 在指定的范围内忽略缩进规则
indentExclusionRanges: []
});
......
}
}
在下文开始之前,先了解几个名词的区别:
- Expression(表达式)
表达式是能够计算出一个值的代码结构。例子:5 + 3是一个表达式,返回计算结果 8;x * y是一个表达式,返回 x 与 y 的乘积;a > b是一个表达式,返回布尔值 true 或 false。
- Statement(语句)
语句是执行一个动作的完整命令,是程序执行的最小单元,是命令编程语言如何执行操作的基础。例子:let x = 10是一个声明语句;x = 5 + 3是一个赋值语句;if (x > y) { ... }是一个控制语句。
- Declaration(声明)
声明是告诉编译器或解释器某个常量、变量或者函数等的存在。例子:const x声明了一个常量 x;function foo() { ... }声明了一个函数 foo。
- Specifier(说明符)
通常与 import 语句相关,指的是从其他模块导入特定绑定的方式。例子:import { name } from 'module'中 name 是一个说明符。
- Reference(引用)
表明一个变量是否可引用或对象成员是否为引用。例子:const x = 1中 x 可引用;{ [y]: '2' }中 y 是引用;{ z: '3' }中 z 不是引用;obj.a是引用;obj['a']不是引用,但 obj 为引用;class Foo { bar() { ... } }中 bar 不是引用;export { foo as bar }中 bar 不是引用;
parse
第 60 行执行 this.parse 函数得到了 statements 数组,第 305 行定义了 this.parse 函数,函数首先判断 this.ast 是否存在,不存在则使用 acorn 生成抽象语法树 AST。
if ( !this.ast ) {
// Try to extract a list of top-level statements/declarations. If
// the parse fails, attach file info and abort
try {
this.ast = parse( this.code, assign({
ecmaVersion: 6,
sourceType: 'module',
......,
}, this.bundle.acornOptions ));
} catch ( err ) {
err.code = 'PARSE_ERROR';
err.file = this.id; // see above - not necessarily true, but true enough
err.message += ` in ${this.id}`;
throw err;
}
}
生成的 AST 类似这样:
Node {
type: 'Program',
sourceType: 'module',
start: 0,
end: 295,
body: [
Node {
type: 'VariableDeclaration',
start: 87,
end: 108,
declarations: [Array],
kind: 'const'
},
......
]
}
可以参考这个仓库 estree 了解解析生成的抽象语法树节点。
第 325 行使用 walk 方法(引入依赖 estree-walker)深度遍历 this.ast。这次遍历可以提前消除 if 语句能直接判定结果的分支,对于三元条件判断语句也是一样。
walk( this.ast, {
enter: node => { ...... }
leave: node => { ...... }
}
例如这段代码:
if (0) {
console.log(0)
}
打包时会直接将上面这段代码删除,又比如:
if (1) {
console.log(1)
} else {
console.log(0)
}
打包出来的代码会是:
if (1) { console.log(1) } else {}
对于三元条件运算符:
const exp = 1 ? 1 : 0
打包出来的代码会是:
const exp = 1
walk 方法执行完成之后继续遍历 this.ast.body (不是深度遍历,不会遍历子节点),在遍历过程中,如果节点类型是 EmptyStatement 跳过不处理;如果节点类型是 ExportNamedDeclaration,节点声明类型为 VariableDeclaration,node.declaration.declarations 存在且长度大于 1,则创建一个自定义节点 syntheticNode。
if (
node.type === 'ExportNamedDeclaration' &&
node.declaration &&
node.declaration.type === 'VariableDeclaration' &&
node.declaration.declarations &&
node.declaration.declarations.length > 1
) {
// push a synthetic export declaration
const syntheticNode = {
type: 'ExportNamedDeclaration',
specifiers: node.declaration.declarations.map(declarator => {
const id = { name: declarator.id.name }
return {
local: id,
exported: id
}
}),
isSynthetic: true
}
const statement = new Statement(syntheticNode, this, node.start, node.end)
statements.push(statement)
this.magicString.remove(node.start, node.declaration.start)
node = node.declaration
}
下面是一个例子:
export const a = 1, b = 2
这样的代码生成的自定义节点 syntheticNode 长这样:
{
type: 'ExportNamedDeclaration',
specifiers: [
{ local: { name: 'a' }, exported: { name: 'a' } },
{ local: { name: 'b' }, exported: { name: 'b' } }
],
isSynthetic: true
}
最后使用自定义节点 syntheticNode 生成 Statement 类的实例并将其添加到 statements 数组中,并在 this.magicString 中对应位置将 export 关键字删除,将目前正在处理的 AST 节点替换为 node.declaration。
src/Statement.js 第 11 行定义了
Statement类,其中第 19 行使用Scope类创建实例变量scope来管理作用域,第 27 行this.isImportDeclaration标识了是否为导入声明,第 28 行this.isExportDeclaration标识了是否为导出声明,第 35 行定义了firstPass预处理方法等。
接下来,如果节点类型是 VariableDeclaration 且 node.declaration.declarations 长度大于 1,则遍历 node.declaration.declarations 生成自定义节点,这一步将多个声明拆成了单个声明,并在除 lastStatement 不存在或者非自定义节点的情况下将用于声明变量的关键字 var 等删除。
if (node.type === 'VariableDeclaration' && node.declarations.length > 1) {
const lastStatement = statements[ statements.length - 1 ];
if ( !lastStatement || !lastStatement.node.isSynthetic ) {
this.magicString.remove( node.start, node.declarations[0].start );
}
node.declarations.forEach(declarator => {
const { start, end } = declarator
const syntheticNode = {
type: 'VariableDeclaration',
kind: node.kind,
start,
end,
declarations: [declarator],
isSynthetic: true
}
const statement = new Statement(syntheticNode, this, start, end)
statements.push(statement)
})
......
} else {
......
}
上面 export 的例子中将节点类型替换成了 VariableDeclaration 并且 node.declaration.declarations 长度大于 1,它拆开后的单个声明自定义节点是:
{
type: 'VariableDeclaration',
kind: 'const',
start: 13,
end: 18,
declarations: [
Node {
type: 'VariableDeclarator',
start: 13,
end: 18,
id: Node { type: 'Identifier', start: 13, end: 14, name: 'a' },
init: Node { type: 'Literal', start: 17, end: 18, value: 1, raw: '1' }
}
],
isSynthetic: true
}
最后同样使用自定义节点 syntheticNode 作为参数生成 Statement 的实例并将其添加到 statements 数组中。
需要注意的是,以上两种情况,只有类型是 VariableDeclaration 并且 node.declaration.declarations 长度大于 1 才会进行处理。除此之外,其他的节点都不会生成自定义节点,而是直接作为入参生成 Statement 的实例添加到 statements 数组中。
......
else {
......
const statement = new Statement( node, this, start, end );
statements.push( statement );
......
}
......
最后遍历 statements 数组为 statement 指定 next 参数,然后将 statements 数组返回。
......
let i = statements.length;
let next = this.code.length;
while ( i-- ) {
statements[i].next = next;
if ( !statements[i].isSynthetic ) next = statements[i].start;
}
return statements;
......
至此 src/Module.js 第 60 行的 this.parse 方法执行完成得到了 statements 数组。
analyse
src/Module.js 第 63 行执行了 this.analyse 方法,这个方法定义在第 184 行,它会遍历 statements 数组中的每个 statement,发现 module 的 import 和 export 声明等。
analyse () {
// discover this module's imports and exports
this.statements.forEach( statement => {
if ( statement.isImportDeclaration ) this.addImport( statement );
else if ( statement.isExportDeclaration ) this.addExport( statement );
......
});
}
在 src/Statement.js 第 27 行和 28 行可以找到判断导入导出的方法:
......
this.isImportDeclaration = node.type === 'ImportDeclaration';
this.isExportDeclaration = /^Export/.test( node.type );
......
import
如果 statement 是 import 声明则执行 this.addImport ,在 this.imports 和 this.sources 中添加记录。
addImport ( statement ) {
const node = statement.node;
const source = node.source.value;
if ( !~this.sources.indexOf( source ) ) this.sources.push( source );
node.specifiers.forEach( specifier => {
const localName = specifier.local.name;
if ( this.imports[ localName ] ) {
const err = new Error( `Duplicated import '${localName}'` );
err.file = this.id;
err.loc = getLocation( this.code, specifier.start );
throw err;
}
const isDefault = specifier.type === 'ImportDefaultSpecifier';
const isNamespace = specifier.type === 'ImportNamespaceSpecifier';
const name = isDefault ? 'default' : isNamespace ? '*' : specifier.imported.name;
this.imports[ localName ] = { source, name, module: null };
})
}
第 161 行 node.source 的例子如下,由此可见 this.sources 中是所有引入依赖的路径。
source: Node {
type: 'Literal',
start: 53,
end: 64,
value: './compute',
raw: "'./compute'"
}
node.specifiers 是一个说明符数组,三种 import 说明符如下:
// ImportSpecifier
import { foo } from './foo'
// ImportDefaultSpecifier
import foo from './foo'
// ImportNamespaceSpecifier
import * as foo from './foo'
下面的例子中就包括一个 ImportDefaultSpecifier 和 ImportSpecifier。
import compute, { name } from './compute'
下面对应的是 node.specifiers
specifiers: [
Node {
type: 'ImportDefaultSpecifier',
start: 7,
end: 14,
local: Node { type: 'Identifier', start: 7, end: 14, name: 'compute' }
},
Node {
type: 'ImportSpecifier',
start: 18,
end: 22,
imported: Node { type: 'Identifier', start: 18, end: 22, name: 'name' },
local: Node { type: 'Identifier', start: 18, end: 22, name: 'name' }
}
]
最后会以 specifier.local.name 为键名在 this.imports 中保存一条记录,对应保存的值是一个对象,对象的 source 属性取 node.source.value,name 属性设置为 'default'、 '*' 或者 specifier.imported.name,属性 module 暂时设置为 null,后续 node.source.value 对应的 module 创建成功后会做补充绑定。
export
如果 statement 是 export 声明,会执行第 188 行的 addExport 方法,export 类型有 ExportAllDeclaration、ExportDefaultDeclaration 、ExportNamedDeclaration,下面针对几种情况进行讨论。
第一是从其它文件导出,分为导出全部和部分导出,导出全部时在 this.exportAllSources 添加记录,导出部分时在 this.reexports 中添加记录,两者都将在 this.sources 中添加记录。
export { name } from './other.js'
export * from './other.js'
const node = statement.node
const source = node.source && node.source.value
// export { name } from './other.js'
if (source) {
if (!~this.sources.indexOf(source)) this.sources.push(source)
if (node.type === 'ExportAllDeclaration') {
// Store `export * from '...'` statements in an array of delegates.
// When an unknown import is encountered, we see if one of them can satisfy it.
this.exportAllSources.push(source)
} else {
node.specifiers.forEach(specifier => {
const name = specifier.exported.name
if (this.exports[name] || this.reexports[name]) {
throw new Error(`A module cannot have multiple exports with the same name ('${name}')`)
}
this.reexports[name] = {
start: specifier.start,
source,
localName: specifier.local.name,
module: null // filled in later
}
})
}
}
第二 export 类型为 ExportDefaultDeclaration 时,设置 this.exports.default,同时设置 this.declarations.default。
export default function foo () {}
export default foo
export default 42
if (node.type === 'ExportDefaultDeclaration') {
const identifier = (node.declaration.id && node.declaration.id.name) || node.declaration.name
if (this.exports.default) {
// TODO indicate location
throw new Error('A module can only have one default export')
}
this.exports.default = {
localName: 'default',
identifier
}
// create a synthetic declaration
this.declarations.default = new SyntheticDefaultDeclaration(node, statement, identifier || this.basename())
}
src/Declaration.js 第 81 行定义了
SyntheticDefaultDeclaration类用于创建自定义默认声明。
第三为 ExportNamedDeclaration 类型且 node.declaration 存在时,在 this.exports 中添加记录。
export var { foo, bar } = { foo: 1, bar: 2 }
export var foo = 42
export function foo () {}
export var a = 1, b = 2, c = 3
if (node.declaration) {
const declaration = node.declaration
if (declaration.type === 'VariableDeclaration') {
declaration.declarations.forEach(decl => {
extractNames(decl.id).forEach(localName => {
this.exports[localName] = { localName }
})
})
} else {
// export function foo () {}
const localName = declaration.id.name
this.exports[localName] = { localName }
}
}
第四为 ExportNamedDeclaration 类型且 node.specifiers.length 存在时,同样在 this.exports 中添加记录。
export { foo, bar, baz }
if (node.specifiers.length) {
node.specifiers.forEach(specifier => {
const localName = specifier.local.name
const exportedName = specifier.exported.name
if (this.exports[exportedName] || this.reexports[exportedName]) {
throw new Error(`A module cannot have multiple exports with the same name ('${exportedName}')`)
}
this.exports[exportedName] = { localName }
})
} else {
this.bundle.onwarn(`Module ${this.id} has an empty export declaration`)
}
first pass
接下来第 189 行执行 statement.firstPass 方法。
analyse () {
this.statements.forEach( statement => {
......
statement.firstPass();
......
});
}
这个函数定义在 src/Statement.js 第 35 行,第 39 行执行了 attachScopes 方法关联作用域,src/ast/attachScopes.js 第 9 行定义并导出了 attachScopes 方法。
export default function attachScopes(statement) {
let { node, scope } = statement
walk(node, {
enter() { ...... }
leave() { ...... }
})
}
在关联作用域时使用 estree-walker 深度遍历当前语句的节点,首先判断如果节点类型是 FunctionDeclaration 或者 ClassDeclaration 则调用语句作用域实例 scope 的 addDeclaration 方法添加声明。src/ast/Scope.js 第 25 行定义了 addDeclaration 方法,在这个方法中,块级作用域中的非块级作用域声明需要向上寻找父作用域添加声明,否则在当前作用域添加声明,其中调用的 Declaration 类在 src/Declaration.js 中第 8 行定义。
// function foo () {...}
// class Foo {...}
if (/(Function|Class)Declaration/.test(node.type)) {
scope.addDeclaration(node, false, false)
}
......
addDeclaration(node, isBlockDeclaration, isVar) {
if (!isBlockDeclaration && this.isBlockScope) {
// it's a `var` or function node, and this
// is a block scope, so we need to go up
this.parent.addDeclaration(node, isBlockDeclaration, isVar)
} else {
extractNames(node.id).forEach(name => {
this.declarations[name] = new Declaration(node, false, this.statement)
})
}
}
......
然后判断如果节点类型是 VariableDeclaration 则遍历 declarations 调用语句作用域实例的 addDeclaration 方法添加声明。
// var foo = 1, bar = 2
if (node.type === 'VariableDeclaration') {
const isBlockDeclaration = blockDeclarations[node.kind]
node.declarations.forEach(declarator => {
scope.addDeclaration(declarator, isBlockDeclaration, true)
})
}
接下来就涉及到创建新的作用域,比如下面的函数作用域,如果是函数或类的声明或表达式则创建函数作用域,并将函数参数 params 声明也添加到函数作用域,标记函数作用域的 block 属性为 false。当节点类型是 FunctionExpression 或 ClassExpression 并且节点 id 存在时将声明也归属到函数作用域( const foo = function fun() {} )。
let newScope
// create new function scope
if (/(Function|Class)/.test(node.type)) {
newScope = new Scope({
parent: scope,
block: false,
params: node.params
})
// named function expressions - the name is considered
// part of the function's scope
if (/(Function|Class)Expression/.test(node.type) && node.id) {
newScope.addDeclaration(node, false, false)
}
}
如果节点类型为 BlockStatement 且父级不存在或者父级节点类型不为函数(因为函数的 body 类型是 BlockStatement,目的是为了和函数作用域作区分),那么创建块级作用域。
// create new block scope
if (node.type === 'BlockStatement' && (!parent || !/Function/.test(parent.type))) {
newScope = new Scope({
parent: scope,
block: true
})
}
如果节点类型为 CatchClause 那么创建块级作用域(单独处理这个条件是因为 CatchClause 有可能存在参数 param)。
// catch clause has its own block scope
if (node.type === 'CatchClause') {
newScope = new Scope({
parent: scope,
params: [node.param],
block: true
})
}
以上创建的新作用域都把 parent 属性设置为了旧作用域,新作用域创建成功后也设置了节点的 _scope 属性为新作用域,scope 变量值也设置为了新作用域,这是因为 estree-walker 是深度遍历,遍历到子节点时要用新作用域,等到 enter 结束触发 leave 时,需要一层层的恢复原作用域。
......
enter( node, parent ) {
......
if ( newScope ) {
Object.defineProperty( node, '_scope', {
value: newScope,
configurable: true
});
scope = newScope;
}
},
leave( node ) {
if ( node._scope ) {
scope = scope.parent;
}
}
......
接下来就是一些细节上的处理,比如检查是否执行了 eval 函数,是的话则提示有安全风险;如果节点类型是 ExportNamedDeclaration 并且 node.source 存在证明是从其他模块的导出,可以跳过;如果节点类型是 TemplateElement 则将节点开始结束范围加入到 stringLiteralRanges 数组中,如果节点类型是 Literal 并且节点值类型是字符串且字符串中包括换行符时,将节点开始加 1 结束减 1 范围加入到 stringLiteralRanges 数组中,比如下方的例子,这样做的目的是后续在处理代码时对指定的这些范围忽略缩进规则。
const a = `12
3`
const c = "121 \
23"
如果使用了 this 语法即节点类型是 ThisExpression 且不是在函数内(通过 contextDepth 是否为 0 判断)使用的,提示错误信息;设置作用域;当前节点是函数则 contextDepth 加 1(离开当前节点时需要减回去)。
判断当前节点的父节点是否为修改型的节点,是的话则取对应的子节点判断和当前节点是一致的,通过 while 循环寻找 type 是否为 MemberExpression 查看修改的深度,如果深度为 0 则为重新分配值,将 isReassignment 设置为 true。
判断当前节点是否为引用或可引用,如果是则创建 Reference 类的实例 reference,将 reference 实例添加到 references 数组中,上文中已经给出节点是引用或可引用的例子。
回到 src/Module.js 第 191 行执行 statement.scope.eachDeclaration 将作用域的声明全部添加到了 this.declarations 中。
analyse () {
this.statements.forEach( statement => {
......
statement.scope.eachDeclaration( ( name, declaration ) => {
this.declarations[ name ] = declaration;
});
});
}
至此 analyse() 执行完成分析结束,Module 类实例创建成功。
Fetch All Dependencies
回到 src/Bundle.js 第 219 行,module 实例创建成功后,在 this.modules 中加入 module 实例,并以 id 即文件路径为键名,以 module 实例为键值,在 this.moduleById 中添加了一条记录。
this.modules.push( module );
this.moduleById.set( id, module );
接着调用 this.fetchAllDependencies 方法拉取当前模块依赖,这个方法定义在第 243 行,它调用了 mapSequence 函数并传入了 module.sources 和一个处理函数作为参数,mapSequence 的作用其实就是遍历 module.sources 将其中的值作为参数传入处理函数,处理函数会返回 Promise,执行下一个处理函数时会等这个 Promise 状态变为 Fulfilled 才会继续,最终返回保存所有处理函数结果的数组(也是 Promise)。
module.sources 保存的 source 是上文提到过的 node.source.value,也就是 import 或者 export 时 from 后面的那个文件路径,处理函数会使用上文提到过的 this.resolveId 去解析 source 对应的路径,如果 source 是绝对路径或者相对路径那么会正常解析同时递归地执行 this.fetchModule 方法去拉取依赖对应的模块,模块里面再去拉取依赖,否则认为 source 是外部路径并创建外部模块 ExternalModule 实例并缓存在 this.externalModules 和 this.moduleById 中。两种情况都会将 source 的解析结果缓存在 module.resolvedIds 中。
fetchAllDependencies(module) {
return mapSequence(module.sources, source => {
const resolvedId = module.resolvedIds[source]
return (resolvedId ? Promise.resolve(resolvedId) : this.resolveId(source, module.id))
.then(resolvedId => {
const externalId = resolvedId || (
isRelative(source) ? resolve(module.id, '..', source) : source
)
let isExternal = this.isExternal(externalId)
if (!resolvedId && !isExternal) {
if (isRelative(source)) throw new Error(`Could not resolve '${source}' from ${module.id}`)
this.onwarn(`Treating '${source}' as external dependency`)
isExternal = true
}
if (isExternal) {
module.resolvedIds[source] = externalId
if (!this.moduleById.has(externalId)) {
const module = new ExternalModule(externalId, this.getPath(externalId))
this.externalModules.push(module)
this.moduleById.set(externalId, module)
}
} else {
if (resolvedId === module.id) {
throw new Error(`A module cannot import itself (${resolvedId})`)
}
module.resolvedIds[source] = resolvedId
return this.fetchModule(resolvedId, module.id)
}
})
})
}
上述代码说明 rollup-init 本身是不支持解析类似
import vue from 'vue'的,它会把 vue 当做外部路径或者说外部依赖,解析这样的路径需要加入 plugin 的支持。
fetchAllDependencies 方法执行完成后还会遍历 module.exports 的键名,在 module.exportsAll 对象中添加记录,键名为 module.exports 的键名,键值为 module.id,然后遍历 module.exportAllSources 拿到 source 对应的模块,将 exportAllModule.exportsAll 中的记录补充到 module.exportsAll 中,这一步可以明确模块所有导出的来源。
this.fetchAllDependencies(module).then(() => {
keys(module.exports).forEach(name => {
module.exportsAll[name] = module.id
})
module.exportAllSources.forEach(source => {
const id = module.resolvedIds[source]
const exportAllModule = this.moduleById.get(id)
if (exportAllModule.isExternal) return
keys(exportAllModule.exportsAll).forEach(name => {
if (name in module.exportsAll) {
this.onwarn(
`Conflicting namespaces: ${module.id} re-exports '${name}' from both ${module.exportsAll[name]} (will be ignored) and ${exportAllModule.exportsAll[name]}.`
)
}
module.exportsAll[name] = exportAllModule.exportsAll[name]
})
})
return module
})
至此 this.modules 和 this.moduleById 就完整缓存了项目中所有的模块。回到 src/Bundle.js 第 96 行,这里也得到了入口模块。
Binding
src/Bundle.js 第 97 行将 this.entryModule 设置为我们刚刚拿到的入口模块值,然后从第 101 行开始在模块上完善一些绑定,在第 103 行结束。
this.entryModule = entryModule;
this.modules.forEach( module => module.bindImportSpecifiers() );
this.modules.forEach( module => module.bindAliases() );
this.modules.forEach( module => module.bindReferences() );
bindImportSpecifiers 定义在 src/Module.js 第 225 行,主要目的是为上文 this.imports 和 this.reexports 中保存的项设置为 null 的 module 值做补充,根据 this.exportAllSources 设置 this.exportAllModules 值,根据 this.sources 在 this.dependencies 中添加 module。
bindAliases 定义在 src/Module.js 第 204 行,主要目的是添加别名,比如说这样一段代码:
const a = 2
const b = a
声明常量 b 时以 a 赋值,在代码中跟踪到 a 的 declaration 实例后,将 b 的 declaration 实例添加到 a 的 declaration 实例属性 aliases 数组中。
bindReferences 定义在 src/Module.js 第 248 行,如果 this.declarations.default 存在则绑定 this.exports.default.identifier 对应的 declaration 为原始 declaration, 然后遍历 this.statements 给 reference 引用绑定 declaration 属性,如果找不到 reference.name 对应的 declaration,则认为其是全局的。
标记
下文中会出现很多同名的 use 方法和 run 方法,但是调用位置和调用对象不同,需要注意区分。
标记导出声明
src/Bundle.js 第 109 行将首先标记所有导出,使用 getExports 方法获取到所有导出名后再获取声明 declaration,调用声明的 use 方法标记为使用,几种声明的 use 方法基本上是调用语句 statement 的 mark 方法和别名 alias 的 use 方法,具体可在 src/Declaration.js 中查看,而 statement 调用 mark 方法后会设置 this.isIncluded 为 true,并遍历 this.references 调用绑定声明的 use 方法,具体查看 src/Statement.js。
entryModule.getExports().forEach(name => {
const declaration = entryModule.traceExport(name)
declaration.exportName = name
declaration.use()
})
getExports 定义在 src/Module.js 第 277 行,它将 this.exports、this.reexports 中的记录名 name 加入到 exports 对象中,遍历 this.exportAllModules 中的模块调用模块的 getExports 方法获取导出记录名同样加入到 exports 对象中,最后返回 exports 键名数组。
getExports () {
const exports = blank();
keys( this.exports ).forEach( name => {
exports[ name ] = true;
});
keys( this.reexports ).forEach( name => {
exports[ name ] = true;
});
this.exportAllModules.forEach( module => {
module.getExports().forEach( name => {
if ( name !== 'default' ) exports[ name ] = true;
});
});
return keys( exports );
}
标记所有模块(树摇优化)
遍历所有模块调用模块的 run 方法标记语句是否要出现在最后的包中,只要有一个模块的 run 方法返回 true,那么就需要重新遍历所有模块执行 run 方法直到所有模块 run 方法返回 false。
let settled = false
while (!settled) {
settled = true
this.modules.forEach(module => {
if (module.run(this.treeshake)) settled = false
})
}
模块的 run 方法定义在 src/Module.js 第 641 行,如果不进行树摇(treeshake)那么它会去遍历模块的 statements 并调用除导入和自定义导出之外 statement 的 mark 方法标记使用,随后直接返回 false 不执行后续的代码。
run ( treeshake ) {
if ( !treeshake ) {
this.statements.forEach( statement => {
if ( statement.isImportDeclaration || ( statement.isExportDeclaration && statement.node.isSynthetic ) ) return;
statement.mark();
});
return false;
}
let marked = false;
this.statements.forEach( statement => {
marked = statement.run( this.strongDependencies ) || marked;
});
return marked;
}
如果使用树摇优化,则遍历模块的 statements 并调用 statement 的 run 方法,这里只要有一个 statement 执行 run 方法返回 true 那模块的 run 方法就会返回 true,src/Statement.js 第 143 行定义了 run 方法。
export default class Statement {
......
run ( strongDependencies ) {
if ( ( this.ran && this.isIncluded ) || this.isImportDeclaration || this.isFunctionDeclaration ) return;
this.ran = true;
if ( run( this.node, this.scope, this, strongDependencies, false ) ) {
this.mark();
return true;
}
}
.....
}
可以看到它首先判断在运行过并且已经标记为使用、是导入声明或者是函数声明时直接返回 undefined,然后调用 src/utils/run.js 第 53 行定义并导出的 run 方法判断是否需要标记。在 run 方法中主要判断是否有副作用,有副作用的话则需要标记。
判断是否有副作用有五种情况,第一,节点如果为引用,且节点名称是 arguments 则是有副作用的。
if (isReference(node, parent)) {
const flattened = flatten(node)
if (flattened.name === 'arguments') {
hasSideEffect = true
}
......
}
在这个过程中同时完善了 strongDependencies 数组,如果节点为引用且当前作用域没有此引用(名称为 arguments 除外)则调用 statement.module.trace 方法找到声明再依据声明找到对应的模块将其加入到 strongDependencies 数组中。
if (isReference(node, parent)) {
const flattened = flatten(node)
......
else if (!scope.contains(flattened.name)) {
const declaration = statement.module.trace(flattened.name)
if (declaration && !declaration.isExternal) {
const module = declaration.module || declaration.statement.module // TODO is this right?
if (!module.isExternal && !~strongDependencies.indexOf(module)) strongDependencies.push(module)
}
}
}
代码中出现的 flatten 函数定义在 src/ast/flatten.js 中,作用相当于获取类型为 MemberExpression 的节点键名路径 keypath。
export default function flatten ( node ) {
const parts = [];
while ( node.type === 'MemberExpression' ) {
if ( node.computed ) return null;
parts.unshift( node.property.name );
node = node.object;
}
if ( node.type !== 'Identifier' ) return null;
const name = node.name;
parts.unshift( name );
return { name, keypath: parts.join( '.' ) };
}
第二,节点类型是 DebuggerStatement 是有副作用的。
else if ( node.type === 'DebuggerStatement' ) {
hasSideEffect = true;
}
第三,节点类型是 ThrowStatement 且为顶级作用域是有副作用的。
else if ( node.type === 'ThrowStatement' ) {
// we only care about errors thrown at the top level, otherwise
// any function with error checking gets included if called
if ( scope.isTopLevel ) hasSideEffect = true;
}
判断是否为顶级作用域定义在 src/ast/Scope.js 第 12 行,没有父作用域或者父作用域是顶级作用域且为块级作用域视为顶级作用域。
......
this.isTopLevel = !this.parent || ( this.parent.isTopLevel && this.isBlockScope );
......
第四,判断节点类型是 CallExpression 或者 NewExpression 时,执行第 9 行定义的 call 方法去判断是否有副作用。在 call 方法中分情况对是否有副作用进行了判定。
else if ( node.type === 'CallExpression' || node.type === 'NewExpression' ) {
if ( call( node.callee, scope, statement, strongDependencies ) ) {
hasSideEffect = true;
}
}
首先,如果 callee.type 是 Identifier 时,寻找 callee.name 对应的声明,如果声明存在则执行 declaration.run 并传入 strongDependencies,否则在 pureFunctions 中查找,能找到则返回 false。
if ( callee.type === 'Identifier' ) {
const declaration = scope.findDeclaration( callee.name ) || statement.module.trace( callee.name );
if ( declaration ) {
if ( declaration.isNamespace ) {
error({
message: `Cannot call a namespace ('${callee.name}')`,
file: statement.module.id,
pos: callee.start,
loc: getLocation( statement.module.code, callee.start )
});
}
return declaration.run( strongDependencies );
}
return !pureFunctions[ callee.name ];
}
而 declaration 的类一共有四种,其中 SyntheticGlobalDeclaration 和 ExternalDeclaration 执行 run 方法直接返回 true,SyntheticNamespaceDeclaration 没有 run 方法,SyntheticDefaultDeclaration 执行 run 方法如下,可以看到最后仍然是通过拿到对应声明(this.original)或者函数体去执行 run 方法形成递归去判断是否有副作用。
......
run ( strongDependencies ) {
if ( this.original ) {
return this.original.run( strongDependencies );
}
let declaration = this.node.declaration;
while ( declaration.type === 'ParenthesizedExpression' ) declaration = declaration.expression;
if ( /FunctionExpression/.test( declaration.type ) ) {
return run( declaration.body, this.statement.scope, this.statement, strongDependencies, false );
}
// otherwise assume the worst
return true;
}
......
Declaration 执行 run 方法如下,如果是非函数节点则直接返回 true,如果是函数节点则与上面相同拿到函数体执行 run 方法形成递归。
run ( strongDependencies ) {
if ( this.tested ) return this.hasSideEffects;
if ( !this.functionNode ) {
this.hasSideEffects = true; // err on the side of caution. TODO handle unambiguous `var x; x = y => z` cases
} else {
if ( this.running ) return true; // short-circuit infinite loop
this.running = true;
this.hasSideEffects = run( this.functionNode.body, this.functionNode._scope, this.statement, strongDependencies, false );
this.running = false;
}
this.tested = true;
return this.hasSideEffects;
}
然后在 call 方法中判断 /FunctionExpression/.test( callee.type ) 是否为 true,是的话还是执行 run 方法形成递归。
if ( /FunctionExpression/.test( callee.type ) ) {
return run( callee.body, scope, statement, strongDependencies );
}
接着在 call 方法中判断 callee.type 是否为 MemberExpression,是的话则用前面提到的 flatten 方法展开 callee,然后寻找对应的声明 declaration,declaration 存在则说明有副作用,还判断了 !pureFunctions[ flattened.keypath ] 这里应该是处理了一下最坏情况。
if ( callee.type === 'MemberExpression' ) {
const flattened = flatten( callee );
if ( flattened ) {
// if we're calling e.g. Object.keys(thing), there are no side-effects
// TODO make pureFunctions configurable
const declaration = scope.findDeclaration( flattened.name ) || statement.module.trace( flattened.name );
return ( !!declaration || !pureFunctions[ flattened.keypath ] );
}
}
如果在 call 方法中以上情况都不存在则直接返回 true 标记副作用。
最后 src/utils/run.js 第 53 行的 run 方法判断是否是修改型的节点,寻找对应节点的声明依据此来决定是否有副作用。
else if ( isModifierNode( node ) ) {
let subject = node[ modifierNodes[ node.type ] ];
while ( subject.type === 'MemberExpression' ) subject = subject.object;
let declaration = scope.findDeclaration( subject.name );
if ( declaration ) {
if ( declaration.isParam ) hasSideEffect = true;
} else if ( !scope.isTopLevel ) {
hasSideEffect = true;
} else {
declaration = statement.module.trace( subject.name );
if ( !declaration || declaration.isExternal || declaration.isUsed || ( declaration.original && declaration.original.isUsed ) ) {
hasSideEffect = true;
}
}
}
回到 src/Bundle.js 第 124 行,至此标记完成。
排序和消除冲突
排序主要是通过深度遍历所有模块按依赖的顺序添加到一个数组中同时排查是否有循环引用的情况,如果有的话双重遍历数组内的模块,如果数组前面的元素依赖后面的元素则说明模块顺序有误,找到循环引用的父模块提醒用户调整顺序。
解决冲突主要是通过遍历全局、外部模块和模块中的声明,如果其中出现重名,则重新设置名称为原来的名称加上 “$” 和出现的次数。
这两个步骤执行结束之后,src/rollup.js 第 56 行 bundle.build 便执行结束了,接下来就是返回打包结果了,结果包括导入、导出、模块数组,生成输出的 generate 方法和写入文件的 write 方法。
生成输出
执行 src/rollup.js 第 112 行返回结果,调用结果的 generate 方法时可以生成输出。这里的 plugins 处理仍然忽略。
......
function generate ( options ) {
const rendered = bundle.render( options );
bundle.plugins.forEach( plugin => {
if ( plugin.ongenerate ) {
plugin.ongenerate( assign({
bundle: result
}, options ), rendered);
}
});
return rendered;
}
......
调用 plugin.ongenerate 方法,这一步相当于触发生成事件,在最终的输出中添加一些属性,或者提取一些属性都是很有用的。
第 58 行的 bundle.render 方法,定义在 src/Bundle.js 第 292 行,它在第 303 行开始创建 MagicStringBundle 的实例 magicString,然后遍历所有模块调用模块的渲染方法得到模块的可渲染源码添加到 magicString 中,MagicStringBundle 就是 magic-string 包中的 Bundle 类,这个类就是为了用来连接合并多个来源。
模块的渲染方法定义在 src/Module.js 第 450 行,它会遍历模块的 statements 对模块的 magicString 做一些处理。
首先对于未被使用的语句,直接将其移除:
......
if ( !statement.isIncluded ) {
if ( statement.node.type === 'ImportDeclaration' ) {
magicString.remove( statement.node.start, statement.next );
return;
}
magicString.remove( statement.start, statement.next );
return;
}
......
对于纯文本的内容忽略对于缩进的处理:
......
statement.stringLiteralRanges.forEach( range => magicString.indentExclusionRanges.push( range ) );
......
对于导出类型是 ExportNamedDeclaration 的,如果为自定义节点则直接跳过处理,如果节点声明为 null 则直接移除:
......
// skip `export { foo, bar, baz }`
if ( statement.node.type === 'ExportNamedDeclaration' ) {
if ( statement.node.isSynthetic ) return;
if ( statement.node.declaration === null ) {
magicString.remove( statement.start, statement.next );
return;
}
}
......
这里将上文中处理 export const a = 1, b = 2, c = 3 时拆出的单个声明分别使用单个声明变量的方式添加了进去:
......
if ( statement.node.type === 'VariableDeclaration' ) {
......
if ( statement.node.isSynthetic ) {
// insert `var/let/const` if necessary
magicString.insertRight( statement.start, `${statement.node.kind} ` );
magicString.insertLeft( statement.end, ';' );
magicString.overwrite( statement.end, statement.next, '\n' ); // TODO account for trailing newlines
}
}
......
下面将上文解决冲突后的结果反应到代码里面,即替换 magicString 中的变量名,另外如果在引用的作用域中仍存在同名变量名,需要将变量名后面加 $$ 后在 magicString 中进行替换:
......
const toDeshadow = blank();
statement.references.forEach( reference => {
const { start, end } = reference;
if ( reference.isUndefined ) {
magicString.overwrite( start, end, 'undefined', true );
}
const declaration = reference.declaration;
if ( declaration ) {
const name = declaration.render( es );
if ( reference.name === name && name.length === end - start ) return;
reference.rewritten = true;
// prevent local variables from shadowing renamed references
const identifier = name.match( /[^\.]+/ )[0];
if ( reference.scope.contains( identifier ) ) {
toDeshadow[ identifier ] = `${identifier}$$`;
}
if ( reference.isShorthandProperty ) {
magicString.insertLeft( end, `: ${name}` );
} else {
magicString.overwrite( start, end, name, true );
}
}
});
if ( keys( toDeshadow ).length ) {
statement.references.forEach( reference => {
if ( !reference.rewritten && reference.name in toDeshadow ) {
const replacement = toDeshadow[ reference.name ];
magicString.overwrite( reference.start, reference.end, reference.isShorthandProperty ? `${reference.name}: ${replacement}` : replacement, true );
}
});
}
......
接着将下面代码示例中的 export 从 magicString 中删除了,并对默认导出做了一些特殊处理,具体查看 src/Module.js 第 595 到 697 行:
export var foo = 42 // 删除 export 关键字
export * from 'external' // 删除整行
export class Foo { ...... } // 删除 export 关键字
然后针对下面示例中需要添加命名空间的地方做了处理:
import * as ns from 'external'
最后去除 magicString 的左右两边空格并返回。
return magicString.trim();
src/Bundle.js 第 329 行根据传入参数中设定的不同输出格式处理 magicString,比如对于 es 格式来说,会在 magicString 中加入引入外部模块的代码,将之前删除的 export 单个变量合写成一个 export 加入到 magicString ,用插件的 transformBundle 处理一遍 code,最后得到可写入的代码 code,如果设置了 sourceMap 为 true 则使用 magicString 生成映射 map,最后返回 { code, map }。
插件在这里也可以介入用 plugin.transformBundle 方法处理 code
写入文件
执行 src/rollup.js 第 112 行返回打包结果,调用结果的 write 方法时可以将输出写入文件。直接查看第 101 行:
......
promises.push( writeFile( dest, code ) );
......
src/utils/fs.js 定义了 writeFile 方法,这个写入文件的方法值得学习,在此记录:
import * as fs from 'fs';
import { dirname } from 'path';
function mkdirpath ( path ) {
const dir = dirname( path );
try {
fs.readdirSync( dir );
} catch ( err ) {
mkdirpath( dir );
fs.mkdirSync( dir );
}
}
export function writeFile ( dest, data ) {
return new Promise( ( fulfil, reject ) => {
mkdirpath( dest );
fs.writeFile( dest, data, err => {
if ( err ) {
reject( err );
} else {
fulfil();
}
});
});
}
最后还是用上文提到的
return Promise.all( promises ).then( () => {
return mapSequence( bundle.plugins.filter( plugin => plugin.onwrite ), plugin => {
return Promise.resolve( plugin.onwrite( assign({ bundle: result }, options ), output));
});
});
执行 plugin.onwrite 相当于触发写入事件
以上即是我对 rollup 初代分析代码的记录
参考:
- rollup-init(pull 下来之后请选择 rollup-init 分支)