计算机二进制数

计算机使用的计算方式和人使用的不同。最重要的区别是计算机中的操作数的精度是有限的而且是固定的。另一个不同之处是计算机使用二进制表示法而不是十进制表示法。
在大多数计算机中,保存数的内存位数是固定的,而且这个位数在计算机设计时就定好了。虽然经过努力,程序员可以使用两倍、三倍或者更多倍的固定位数来表示数,但是这并没有改变问题的本质,计算机本质上是有限的,这就要求我们使用固定的位数来表示数,这样的数我们称为有限精度数(finite-precision-number)。
我们首先来看看用 3 位十进制数表示的正整数集合,不包括小数点和符号位,该集合一共有 1000 个数:000,001,002,003 ··· 999。在这种限制条件下,我们不可能表示出大于集合中最大数(上溢错)或者小于集合中最小数(下溢错)的数。也不能表示出不太大也不太小但是并不是集合中的某个数。
大家都熟悉的普通的十进制数是由一串十进制位和一个小数点(如果有)组成的,其一般形式为:。选择 10 作为求幂的基数(radix)是因为我们使用的十进制数。使用计算机时,使用非 10 的基数更方便一些。最常用的基数是 2、8 和 16。基于这些基数的计数系统分别是二进制、八进制和十六进制。
以 k 为基数的计数系统需要 k 个不同的符号来表示 0~k-1,十进制数就是由下面这 10 个十进制位来表示:0, 1, 2, 3, 4, 5, 6, 7, 8, 9。
所有的二进制数都可以使用两个二进制位来表示:0, 1。使用 0 和 1表示的二进制位通常简称为位(bit)。
对于十六进制数来说,则需要 16 个符号位,因此就需要 6 个新的符号。按照习惯,人们使用 A~F 来表示 9 之后的 6 个数位。这样一来,十六进制数就由下面这些位构成:0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F。
进制转换
八进制或者十六进制数和二进制数之间的转换很容易。把二进制数转换成八进制时,只需要把数中的每 3 位分成一组,小数点左边和右边的 3 位首先分成一组,然后依次分组。每个 3 位组都可以直接转换成单独的八进制位 0~7 中的一个。转换时可能需要在最高位的前面或者最低位的后面添加 0 以形成三位组。把八进制数转换成二进制数也同样简单,只需要把每个八进制位转换成相等的 3 位二进制数。十六进制数和二进制数之间的转换与八进制数和二进制数之间的转换基本相同,不同之处在于每个十六进制需要 4 位二进制数来表示。

把十进制数转为二进制数可以使用两种不同的方法。第一种方法是直接使用二进制的定义,先求出比需要转换的数小的 2 的最大次幂,然后从该数中减去这个幂,对得到的结果重复上述的步骤,只需要把该数分解成 2 的各次幂的和,当某次幂存在时,在相应的位置上填 1,否则就填 0,这样就得到了转换的结果。
另一种只能用于整数的方法是把需要转换的数除以 2,把得到的商写在最初的数的下方,把余数0或者1写在商的旁边。然后对商重复执行该过程,直到商为 0 为止。该过程最终会得到两列数,商和余数。从低位向上看余数列就是转换之后的二进制数。

二进制数转换成十进制数也有两种不同的方法。一种是把二进制数中为 1 的位乘以 2 的相应次幂,再把所有结果相加。例如:。
另一种方法步骤如下,首先把二进制数按垂直方向写下来,每位占一行,最左边的位在最底部。第 n 行的对应值等于第 n-1 行的值乘以 2 再加上第 n 行的位值(0或者1)。最高行的对应值就是转换得到的十进制数。
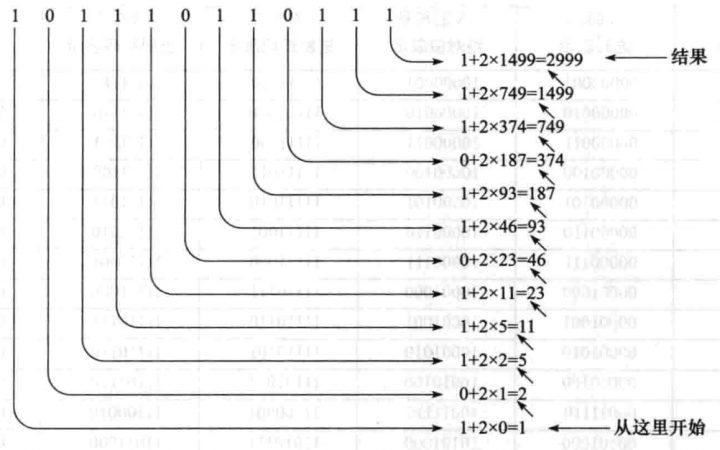
把十进制数转换成八进制数或者十六进制数可以先把十进制数转换成二进制数,再把二进制数转换成需要的进制。也可以通过刚才讨论的通过减去 8 或 16 的幂的方法来实现。
刚才讨论的都是整数的进制转换,现在我们来讨论十进制小数转二进制小数的方法。可以通过减去 2 的负数次幂的方法来实现。也可以通过把需要转换的数乘以 2,把得到的积写在最初的数的下方,如果向整数位有进位则把 1 写在积的旁边,向整数位没有进位则把 0 写在积的旁边,然后重复该过程直到小数为 0,过程中向整数的进位不参与乘 2 运算,该过程最终会得到两列数,积和向整数的进位。从高位向下看就是转换之后的二进制数。

二进制小数转十进制小数也有两种方法,一种方法是把二进制数中为 1 的位乘以 2 的相应负数次幂,与整数不同的是小数的负数次幂从 -1 开始递减。例如:
另一种方法步骤如下,首先把二进制数按垂直方向写下来,每位占一行,最右边的位在最顶部。第 n 行的对应值等于第 n-1 行的值除以 2 再加上第 n 行的位值(0或者1)。最底行的对应值就是转换得到的十进制数。

二进制负数
在电子数字计算机的发展历史中曾经出现过 4 种不同的负数表示法。第一种是符号绝对值法。在这种表示方法中,最左边的位是符号位(0表示正数,1表示负数),其余的位是该数的绝对值。
第二种表示法是二进制反码(one's complement),二进制反码同样使用符号位,0 表示正数,1 表示负数。求某个数的相反数时,把每个 1 替换成 0 而把 0 替换成 1。二进制反码现在已经不使用了。
第三种表示法是二进制补码(two's complement),同样使用符号位,符号位为 0 表示正数,1 表示负数。求某个数的相反数时,第一步把每个 1 替换成 0 而把 0 替换成 1,这一步和二进制反码一样。第二步把第一步的结果加 1。例如:
0000 0110 (+6)
1111 1001 (-6的二进制反码表示)
1111 1010 (-6的二进制补码表示)
如果最高位产生进位,将被丢弃。
第四种表示法是余(excess )表示法,每个数都用自身和的和表示,举个例子,如果要表示 8 位数,m=8,也就是余 128 表示法,每个数的存储值都是它的真值加上 128。这样一来,-3 就成了 -3 + 128 = 125,因此 -3 就用八位二进制数 125(01111101)来表示。使用这种表示法,-128~+127 之间的数就被映射到 0~255之间,这样它们就都可以表示成 8 位正整数。有趣的是,这种表示法的结果和二进制补码相同,只是它们的符号位相反。
在符号绝对值法和反码表示法中,0 都有两个值:正 0 和负 0。这种情况是我们不希望看到的。二进制补码表示法就没有这个问题,正 0 的二进制补码还是正 0,二进制补码有一个特别之处,一个 1 后面全是 0 的数的补码是它本身,我们用它来表示 -128。这使得补码的正数和负数的表示范围不对称,有一个负数没有相应的正数和它对应。
二进制运算
二进制加法和十进制的加法一样,从最右边开始把加数和被加数的对应位相加。如果产生了进位,就向左进一位。
对于人脑来说,我们在进行十进制运算时可以知道第一位是符号,从而区分加减操作,而对于计算机来说要设计的尽量简单,而让计算机去辨别符号位显然会让基础电路变得很复杂,于是人们想出了让符号位参与运算来简化计算机设计。
如果用符号位绝对值表示法让符号位参与运算,例如:
1 - 1 = 0000 0001 + 1000 0001 = 1000 0010 = -2
显然结果是不正确的,为了解决这个问题,出现了反码,例如:
1 - 1 = 0000 0001 + 1111 1110 = 1111 1111 = -0
可以看出来结果虽然正确,但是 0 带符号是没有任何意义的,因为会有 0000 0000 和 1111 1111 表示正 0 和 负 0。于是补码的出现解决这个问题,例如:
1 - 1 = 0000 0001 + 1111 1111 = 0000 0000 = 0
简单了解了二进制运算之后,接下来我们来推导一下使用二进制反码运算的运算规律。
设有两个 n 位的二进制数分别为 和 ,则其反码分别为 和 ,相加需要满足下式:
(1)
依据此式进行分类讨论:
1.,,此时 (1) 式中左右两边显然成立;
2.X,Y 异号,此时: (2)
若 ,则 ,此时 (2) 式会溢出,舍去其最高位(相当于减去 ),再加上 1,即可得到对应的结果。该过程被称为循环进位(end-around carry)。
若 ,则 ,与 (2) 式对应,此时不会产生进位;
3.,,此时有:
(3)
而 (4)
此时 (4) 式会溢出,将 (4) 式舍掉进位 再加 1 即可得到 (3) 式中的结果,该过程与第 2 类中的过程一样进行循环进位。
补码加法与反码加法的推导基本相同,其对于最高位的处理更简单,直接丢弃就可以了,不用进行加 1 操作。
其实,巧妙地利用反码和补码让符号位参与运算,将减法变成加法,其背后还蕴含了数学原理。
将钟表想象成是一个 1 位的 12 进制数,如果当前时间是 6 点,我希望将时间设置成 4 点,需要怎么做呢?我们可以:
1.往回拨 2 个小时 6 - 2 = 4
2.往前拨 10 个小时 (6 + 10) mod 12 = 4
3.往前拨 22 个小时 (6 + 22) mod 12 = 4
其中 mod 代表取模操作,16 mod 12 表示 16 除以 12 的余数。
所以钟表往回拨(减法)的结果可以用往前拨(加法)替代。接下来介绍数学中的一个相关概念——同余,最先引用同余的概念与符号者为德国数学家高斯。同余理论是初等数论的重要组成部分,是研究整数问题的重要工具之一。
同余的概念
两个整数 a 和 b,若它们除以整数 m 所得的余数相等,则称 a 和 b 对于模 m 同余,记作 ,读作 a 与 b 关于模 m 同余。举例说明:
4 mod 12 = 4
16 mod 12 = 4
28 mod 12 = 4
所以称 4、16、28 关于模 12 同余。
负数取模
下面是关于 mod 运算的数学定义:
其中 代表取 x/y 的下界,以 -3 mod 2 为例:
利用公式可以计算出:
(-2) mod 12 = 12 - 2 = 10
(-4) mod 12 = 12 - 4 = 8
(-5) mod 12 = 12 - 5 = 7
再回到时钟的问题上,回拨2小时 = 前拨10小时,回拨4小时 = 前拨8小时,结合上面同余的概念:
(-2) mod 12 = 10
10 mod 12 = 10
-2 和 10 是同余的
(-4) mod 12 = 8
8 mod 12 = 8
-4 和 8 是同余的
要实现用正数替代负数,只需要运用同余数的两个定理:
1.反身性,;
2.线性运算定理,如果,,那么,,。
因此:
再回到二进制反码的运算中:
2 - 1 = 2 + (-1) = 0000 0010 + 1111 1110
1111 1110 十进制为 126,我们会发现有如下规律:
(-1) mod 127 = 126
126 mod 127 = 126
根据上述可推导出:
2-1 和 2+126 的余数结果相同,而这个余数正是我们期望的计算结果。而反码运算的 2+126 就相当于钟表转过了一轮。
补码运算实际上就是在反码的基础上加 1,增加了模的值:
2 - 1 = 2 + (-1) = 0000 0010 + 1111 1111
在二进制运算中,加数和被加数的符号位相反的情况下不会发生溢出。如果它们的符号位相同而结果的符号位与它们相反,就说明发生了溢出而且结果是错误的。无论使用反码还是补码,当且仅当结果符号位的进位和符号位产生的进位不同时会产生溢出。
浮点数
在许多计算中,使用的数的范围都相当大。例如,在天文学的计算中,可能会涉及电子的质量 ,太阳的质量 ,相差的范围达到了 。这两个数可以表示成:
0000 0000 0000 0000 0000 0000 0000 0000 00.0000 0000 0000 0000 0000 0000 0009
2000 0000 0000 0000 0000 0000 0000 0000 00.0000 0000 0000 0000 0000 0000 0000
这两个数进行计算时必须保证小数点前有 34 位,后面有 28 位,这样结果就可能有 62 位有效数字。实际上,很少有测量结果需要 62 位有效数字的,虽然我们可以对所有的中间计算结果保留 62 位有效数字,在打印最后结果之前舍去其中的 50 位或者 60 位,但是这样不仅浪费 CPU 的计算时间还会浪费内存。
我们需要的表示法应该能够把数的表示范围和有效数字分开表示,这种被称为浮点数的表示法以物理、化学和工程中常用的科学计数法为基础。
浮点数原理
我们熟悉的科学计数法就是一种把精度和表示范围分开的表示法:,其中 f 称为尾数(fraction 或 mantissa),e 是一个正整数或者负整数,称为阶码(exponent)。计算机中使用这种表示法就称为浮点数。下面是使用浮点数的几个例子:
3.14 = 0.314 * = 3.14 *
0.000001 = 0.1 * = 1.0 *
1941 = 0.1941 * = 1.941 *
阶码的位决定数的表示范围,而尾数的位数决定数的精度。由于可以使用多种方式表示一个数,因此有必要选择一种作为标准。为了研究这种表示法的特点,考虑一种表示法 R,使用带符号的 3 位尾数,表示范围为 或者 0,阶码使用带符号的两位数。这种表示方法的表示范围按绝对值计算从 +0.100 * 到 +0.999 * ,表示范围几乎跨越了 ,但是只使用了五位数字和两个符号位就可以保存一个数。
浮点数可以用于模拟数学中使用的实数,但是两者之间仍然存在着重要的区别。下图给出了实数轴的粗略划分,实数轴可以划分成 7 个区域:
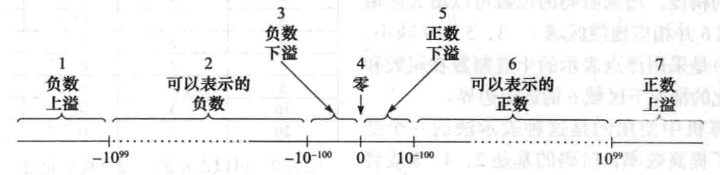
使用三位尾数和两位阶码表示的数和实数之间的主要区别在于前者不能表示区域1、3、5、7中的数。如果算术运算的结果使数字落在了区域 1 或者 7,例如,,就会产生上溢错并导致结果不正确。出现这种问题的原因在于表示法本身的表示能力是有限的,因此出现这种问题也是不可避免的。同样,区域 3 和区域 5 的数也无法表示,这种情况称为下溢错误。和上溢相比,下溢的结果并不严重,因为区域 3 和区域 5 的数通常可以近似于 0 来表示。例如, 的银行余额和 0 并没有什么区别。
浮点数和实数之间的另一个重要区别是它们的密度不同,无论实数 x 和 y 多么接近,它们之间都存在另一个实数。对于任意两个不同的实数 x 和 y,z = (x + y) / 2 是位于它们之间的实数,这就是实数的连续性。而浮点数则没有连续性,比如刚才提到的五位数字、两位符号位的表示法只能表示 (999 - 100 + 1) * (99 + 99 + 1) = 179100 个正数,179100 个负数和 0 (0 可以用多种形式表示),这样一共可以表示 358201 个数。而在 ~ 之间有无限多的实数,而这种表示法只能表示其中的 358201 个数。因此很有可能出现计算的结果不能用这些数来表示的情况,即使数位于区域 2 和区域 6 也一样,这也就是为什么上图这两个区域是用虚线表示。 除以 3 的结果就不能用我们的表示法精确表示。如果计算的结果不能精确表示,那么就需要用最接近它的数来表示,这称为舍入(rounding)。
区域 2 或者区域 6 中可表示的数之间相隔的距离也不是恒定的,比如 ~ 之间的距离显然要大于 ~ 之间的距离。但是,如果使用两个相邻的数之间的比例来表示其距离的话就是恒定的。换句话说,舍入引起的相对误差(relative error)对于大数和小数来说都是近似相等的。
虽然到目前为止,我们讨论的是使用三位尾数、两位阶码的表示法,但是其结论也同样适用于其他表示法。
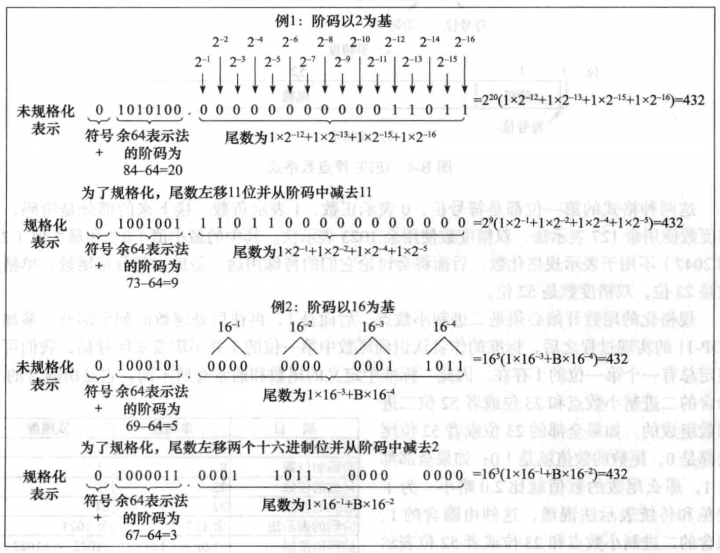
计算机使用的是这种表示法的一个变体,为了提高效率,阶码的基是 2、4、8或者 16 而不是 10,相应的尾数就由二进制串、四进制串、八进制串或者十六进制串组成。如果这些尾数的最高位是 0 ,就把尾数左移一位,并把阶码减一,这样并不会改变数的值(除非出现了下溢),最高位不为 0 的尾数称为规格化(normalized)尾数。
下图给出了使用 2 作为基的规格化浮点数的例子:
IEEE 754 浮点数标准
在 20 世纪 80 年代之前,每个计算机厂商都使用自己的浮点数标准。毫无疑问,它们肯定是不同的。更糟糕的是,其中有些厂商的运算结果不正确,这是由于一般的硬件设计者对于浮点数的细节不了解导致的。
为了改变这种状况,IEEE(Institute of Electrical and Electronics Engineers,电子电气工程师学会)在 20 世纪 70 年代末成立了一个专门委员会负责对浮点数进行标准化。标准的制定目标不仅是可以使浮点数在不同的计算机之间交换而且可以使硬件设计者掌握一个已知正确的计算模式。这些工作的结果就是 IEEE 754 标准(IEEE,1985)。现在大部分 CPU 的浮点指令都符合 IEEE 浮点数标准。
标准中定义了三种格式:单精度(32位)、双精度(64位)和扩展精度(80位)。其中的扩展精度是用于减少舍入误差,主要用在浮点运算单元内部。单精度和双精度格式都使用了以 2 为基的尾数和阶码的余数表示。

这两种格式的第一位都是符号位,0表示正数,1表示负数。接下来的部分是阶码,单精度使用余 127 表示法,双精度使用余 1023 表示法。其中的最小值(0)和最大值(255 和 2047)不用于表示规格化数,后面将会讨论它们的用途。最后一部分是尾数,单精度是 23 位,双精度是 52 位。
这里介绍一下什么是余 127 表示法及为什么使用余 127 位表示法。余 127 表示法就是将实际的阶码加上 127 来存储,比如阶码为 1 时,实际存储的阶码为 1000 0000,阶码为 -1 时,实际存储的阶码为 0111 1110。我们熟悉的还有另外一种表示法,就是将第一位视为符号位,那么 1 则存储为 0000 0001,-1 则视为 1000 0001,如果用这种方法表示就使得一个浮点数中出现了两个符号位。相比于后者,余 127 位表示法更有利于机器比较阶码的大小。
8 位用余 127 位表示法表示的阶码的取值范围是 0~255 (0000 0000 ~ 1111 1111),除去最小值和最大值用于其他特殊用途之外,阶码可用范围为 1~254(0000 0001 ~ 1111 1110),总共有 254 个值。127 与 128 是 254 个值的中位数,这两个数作为偏置均合理。若以 127 为偏置,则阶码的取值范围为 -126~127,若以 128 为偏置,则阶码的取值范围为 -127~126。那么为什么使用 127 作为偏置,我们后面再进行讨论。
规格化的尾数开始必须是二进制小数点,后面是 1,再往后是尾数的剩余部分。标准中定义的尾数和通常有所不同,它是由隐含的 1、隐含的二进制小数点和 23 位二进制数组成的。如果全部的 23 位尾数都是 0,那么尾数的数值就是 1.0,如果全部都为 1,那么尾数的数值就比 2.0 略小。为了避免和传统表示法混淆,这种由隐含的 1、隐含的二进制小数点和 23 位二进制数组成的数称为有效数(significand)而不称为尾数。所有规格化的数都有有效数 s,范围是 。
了解了上述的标准定义,我们就可以分别计算出以 127 或者 128 为偏移的数的取值范围,以 127 为偏置时按绝对值取值范围为 ~ ,中间隔了约 。以 128 为偏置时按绝对值取值范围为 ~ ,中间隔了约 。因为 ,所以以 127 为偏置时可以表示的数据范围更大。这也就回答了为什么使用 127 作为偏置的问题。
下图是 IEEE 754 标准浮点数的特征:
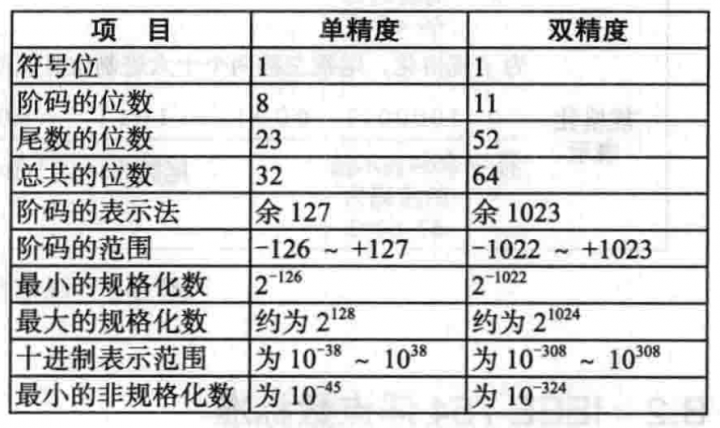
通过查看上图大家可能已经注意到了,最后一行是最小的非规格化数,这就是我们上文提到的当阶码为 0 时所表示的特殊用途。当运算结果的数量级小于规格化浮点数所能表示的最小值时,该表示法就出现了问题。以前,硬件都是采取以下两种策略,或者把结果置为 0 或者产生一个浮点下溢陷阱。这两种处理方法都不令人满意,因此 IEEE 提出了非规格化数。这类数的阶码为 0,尾数由后面的 23 位或者 52 位给出,尾数最左面隐含的 1 现在变成了 0。非规格化数可以很容易和规格化数区别开,因为规格化数的阶码不能为 0。

这种方式用降低精度的方法来处理下溢,这就可以避免出现在结果不能用规格化数表示时直接变成 0 的问题。这种方式可以表示两个 0,一个正 0 和一个负 0,由符号位来决定。
上溢没有一种合理的处理方式。因为左面已经没有可用的组合了。我们可以使用一种特殊的表示法来表示无穷大,由全 1 的阶码(规格化数中不允许出现这样的阶码)和尾数 0 组成。该数可以用作操作数,在进行算术运算时作为无穷大来处理。例如:无穷大加任何数都等于无穷大,任何有限的数除以无穷大都等于 0,与此类似,任何有限数除以 0 都等于无穷大。
那么无穷大除以无穷大等于多少呢?结果没有定义,为了应付这种情况,提供了另外一种特殊的格式,称为 NaN(非数字,Not a number)。
了解了浮点数之后,我们就可以知道为什么在 JavaScript 或者其他的一些语言当中 0.1 + 0.2 = 0.30000000000000004 而不等于 0.3 了,原因就是它们都使用了 IEEE 754 标准的双精度格式表示浮点数。下面我们来验证一下。
首先将 0.1 和 0.2 用二进制的形式表示出来,分别为:
0.0001 1001 1001 1001 1001 ....
0.0011 0011 0011 0011 0011 ....
尾部都存在无限循环,但是计算机存储是有限的,从这里就可以看出来误差的存在。接下来我们把他们转换成 IEEE 754 标准双精度格式分别为:
0 011 1111 011 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001
0 011 1111 100 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001
接下来我们将两数相加:
1.1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 * + 1.1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 * = 1.1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 * + 11.0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 001 * = 100.1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1011 * = 0.0100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1011
根据 IEEE 标准的舍入方法:
- 舍入到最接近:会将结果舍入为最接近且可以表示的值,但是当存在两个数一样接近的时候,则取其中的偶数(在二进制中是以0结尾的);
- 朝正无穷方向舍入;
- 朝负无穷方向舍入;
- 朝0方向舍入。
将结果舍入为0.0100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1101,转换成十进制为:
+ + + + + + + + + + + + + + + + + + + + + + + + = 0.30000000000000004
参考链接:
1.原码反码补码详解
2.反码与补码加法的理解
3.计算机组成:结构化方法